技术教程破解资源
云展网加密书籍算法解密
绪论
(好久没发帖了)
本帖起因
python下载云展网书籍并合并为PDF
https://www.52pojie.cn/thread-1672367-1-1.html
(出处: 吾爱破解论坛)

image-20220808110646193.png
定位
定位到解密代码的位置
这里不赘述,页面里有一个iframe,iframe中为核心预览页,抓包发现有zip文件下载,并且如图所示,请求了zip文件后,继续请求了带有PDFmagic头的blob协议,多半就是本地解密后丢到pdf里运行了。。
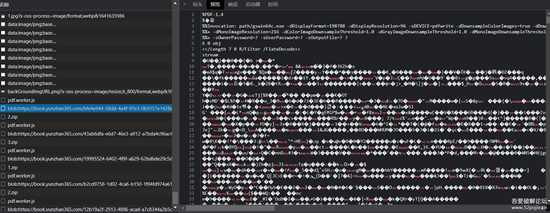
image-20220808111039702.png
PDFjs库不会取消过程中产生的blob链接,新页面打开,发现有密码,
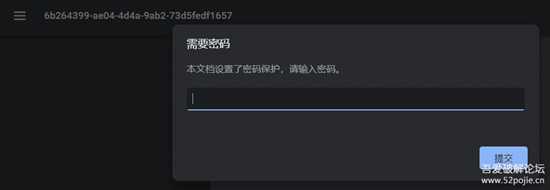
image-20220808111509952.png
根据请求堆栈找一下密码计算的位置,这密码不就有了么
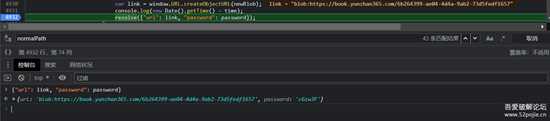
image-20220808111604143.png
啥?不会?(这都不知道就不要学了)行!我录gif动画!
GIF 2022-8-8 11-47-36.gif
还是看不懂?=_=那我确实是没办法了,要不多看看?
然后就是下载zip,解压试一下。。。emmm好像zip文件也加密了,打不开,magic头也不对。
该分析解密部分了。
解密
反正解密的地方都找到了,分析就完了。
试读结束,以下内容为付费阅读部分,请先自觉到文末免费评论,再返回此处继续阅读
(↑↑人与人之间的信任↑↑)
cn.png

love.png
(中国人不骗中国人)
解密的核心代码:
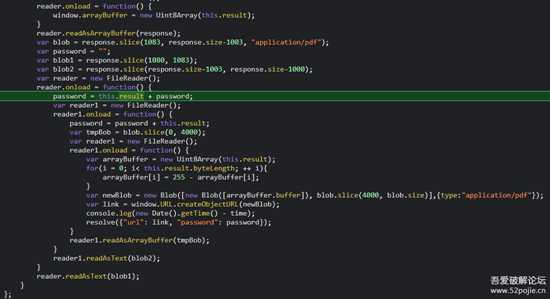
image-20220808120604086.png
请求连接,获取到x.zip文件(图中response,二进制数据,下称:zip数据),
其中,获取到的zip数据 第1083位 至 倒数1003位 为加密后的pdf数据(图中blob定义处)
(好嘛,不是什么所谓的zip文件)
zip数据的 第1080位 至 第1083位 的十六进制字符串为密码的前半截,
后半截为zip数据 倒数第1003位 至 倒数第1000位 的十六进制字符串
两段密码拼接为完整密码
pdf密码到此结束。
pdf文件本身还需要进行解密,
加密后的pdf数据前4000位字节码依次被255减去即为原始数据(似乎就是unsigned int取反)
检验
静态分析完,进行验证。
下载1.zip,16进制打开。
读取第1080位 至 第1083位 的十六进制字符串(注意是10进制),进行对比。
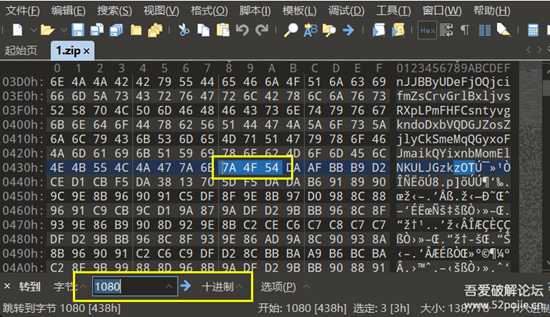
image-20220808121650707.png
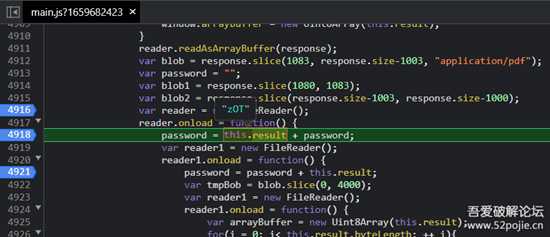
image-20220808121819920.png
读取 倒数第1003位 至 倒数第1000位 的十六进制字符串,进行对比。(注意从文件末尾向前查找)
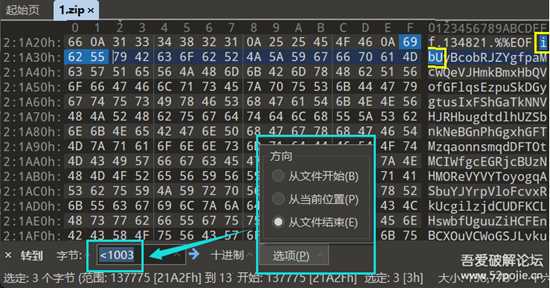
image-20220808122034245.png
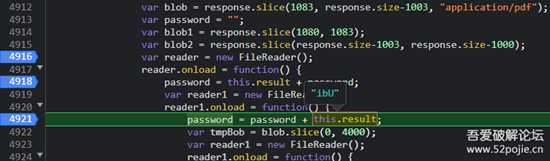
image-20220808122051111.png
大部分编辑器可以通过快捷键
Ctrl + G跳转010 Editor可以通过
<xxx从文件末尾向前进行跳转其余软件请自行斟酌。
随手写个js脚本放到console控制台里跑一下,把解密后的数据粘贴回16进制编辑器。
`DA AF BB B9 D2 CE D1 CB F5 DA 38 13 70 5D F5 DA...............这里省略好多行.....................DA B6 91 89 90 9C 9E 8B 96 90 91 C5 DF 8F 9E 8B`.split(/ |\n/g).filter(a=>a).map(a=>(255-Number("0x"+a)).toString(16)).join(" ")脚本附在上面
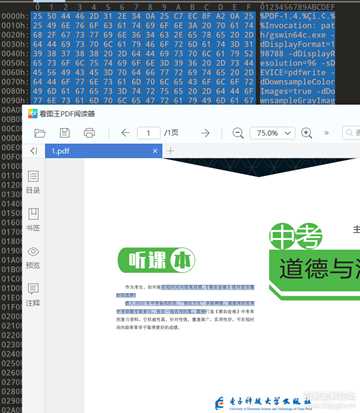
image-20220808123018195.png
输入pdf密码zOTibU,成功解密。
成品
算法都给你了,自己写。